はじめての MCMC、
はじめての Stan
@y__mattu
2018/6/9 Tokyo.R #70 <ベイズ特集会>
誰?
- 松村優哉
- Twitter: y__mattu
- GitHub: ymattu
- M2
- 計量経済学、ベイズ統計、因果推論、マーケティング
- 言語: R, Python, SAS
- https://ymattu.github.io/
- http://y-mattu.hatenablog.com/
- Tokyo.R / Japan.R 運営
![]()
著書(共著)

- 2 部構成
- 第一部(基礎編)
- R 入門
- R のデータハンドリング基礎
- 第二部(応用編)
- テキストマイニング
- R のパフォーマンス向上
- 地理データ解析
- ベイズ最適化入門
- …etc
著書 2
R ユーザのための RStudio[実践]入門
− tidyverse によるモダンな分析フローの世界−

- 通称: 「宇宙本」
- RStudio 入門(@y__mattu)
- スクレイピングによるデータ取得(@y__mattu)
- dplyr を中心としたデータハンドリング(@yutannihilation)
- ggplot2 による可視化(@kyn02666)
- R Markdown によるレポーティング(@kazutan)
よく見る「あれ」が出来上がります
- これを traceplot といいます
- なんか 1 回じゃ心もとないから複数回(chain)やったほうがいいよね
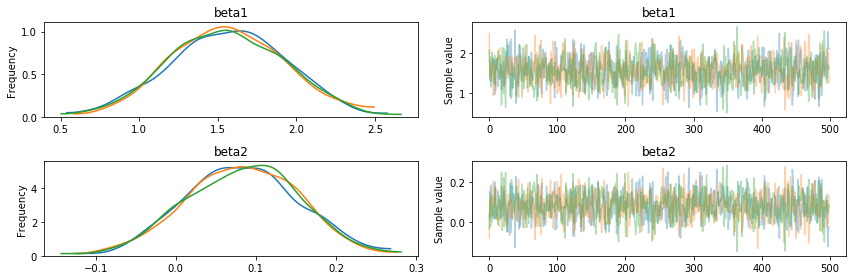
バーンイン
- 最初の方は初期値依存があるので事後分布の形成から省くことが多い
MCMCでの収束
- Geweke の方法
- Geweke統計量Z値を計算し、MCMCのburn-in期間(前半10%)と後半50%を比較し、|Z|値が十分に小さければMCMCが収束したと考える
収束を確認1
トレースプロットを見る
traceplot(fit)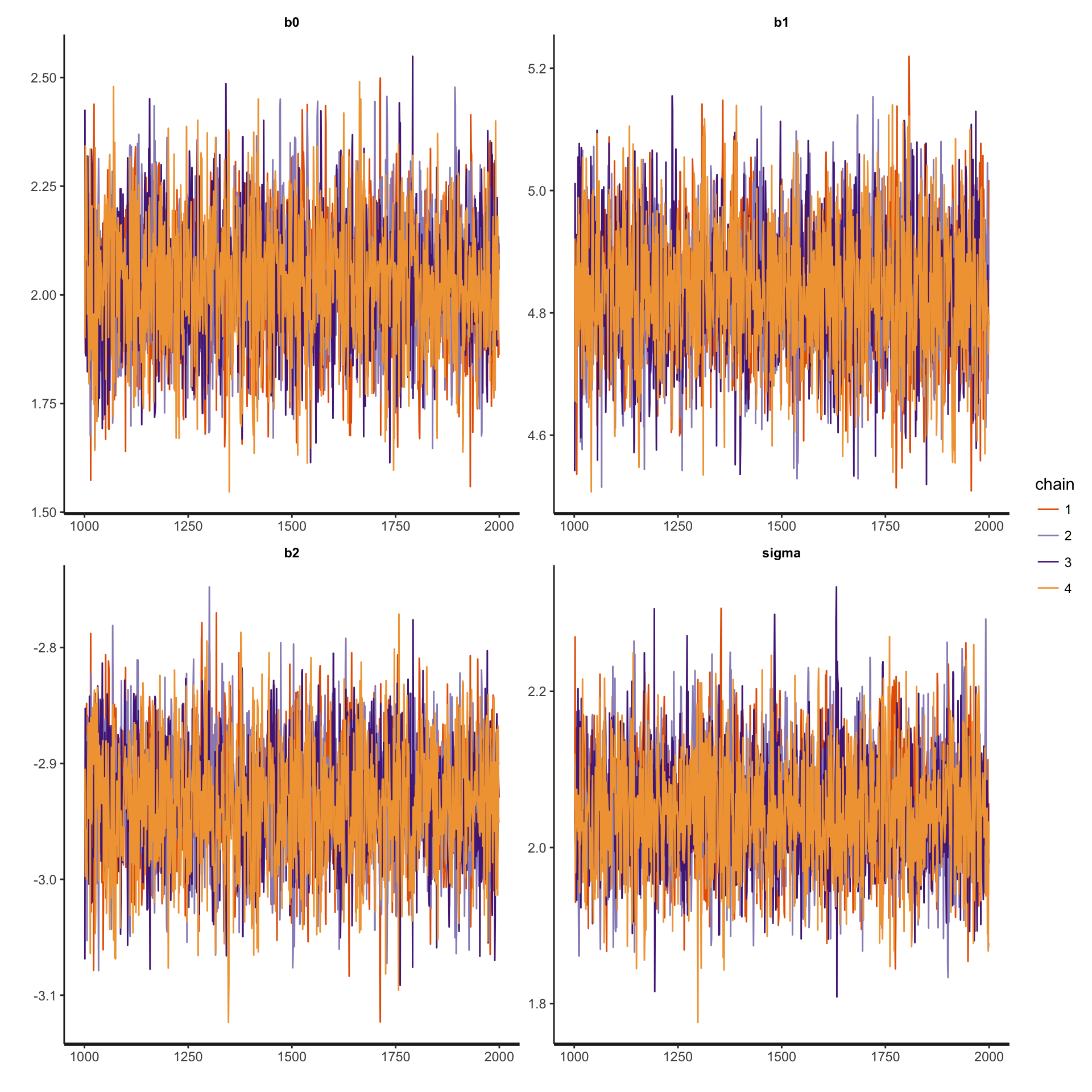
初心者セッション 1-3 をもっと詳しく知りたい人は
R で楽しむベイズ統計

- 通称: サイコロ本
- ベイズの定理から MCMC まで 数学的な面も分かりやすく解説
- わかりやすさと詳細さのバランスがとれた本
初心者セッション 1-3 をもっと詳しく知りたい人は
ベイズ統計モデリング: R,JAGS,Stan によるチュートリアル

- 通称: 犬 4 匹本
- ベイズの定理から MCMC, Stan までわかりやすく解説
- 鈍器なみに分厚いです
初心者セッション 1-3 をもっと詳しく知りたい人は
Stan と R でベイズ統計モデリング

- 通称: アヒル本
- Stan によるベイズモデリングをしっかり、分かりやすく解説
- Stan 使うなら必携