初心者セッション
〜データハンドリング編〜
y__mattu
2019/4/13 Tokyo.R #77
誰?
- 松村優哉
- Twitter: y__mattu
- GitHub: ymattu
- 大学院生
- ベイズ統計、因果推論、マーケティング
- 言語: R, Python, (SAS)
- https://ymattu.github.io/
- http://y-mattu.hatenablog.com/
- Tokyo.R 運営
![]()
著書
R ユーザのための RStudio[実践]入門
− tidyverse によるモダンな分析フローの世界−

通称: 「宇宙本」
- RStudio 入門(@y__mattu)
- スクレイピングによるデータ取得(@y__mattu)
- dplyr を中心としたデータハンドリング(@yutannihilation)
- ggplot2 による可視化(@kyn02666)
- R Markdown によるレポーティング(@kazutan)
本日の主役は

特徴
パッケージを使わないやり方より
- (大きいデータだと特に)
速い - 簡単
≒ わかりやすい - 他のtidyverseのパッケージと相性がいい
EC サイトのログデータ
- を意識して作ったダミーデータ
- https://github.com/ymattu/sampledata_small

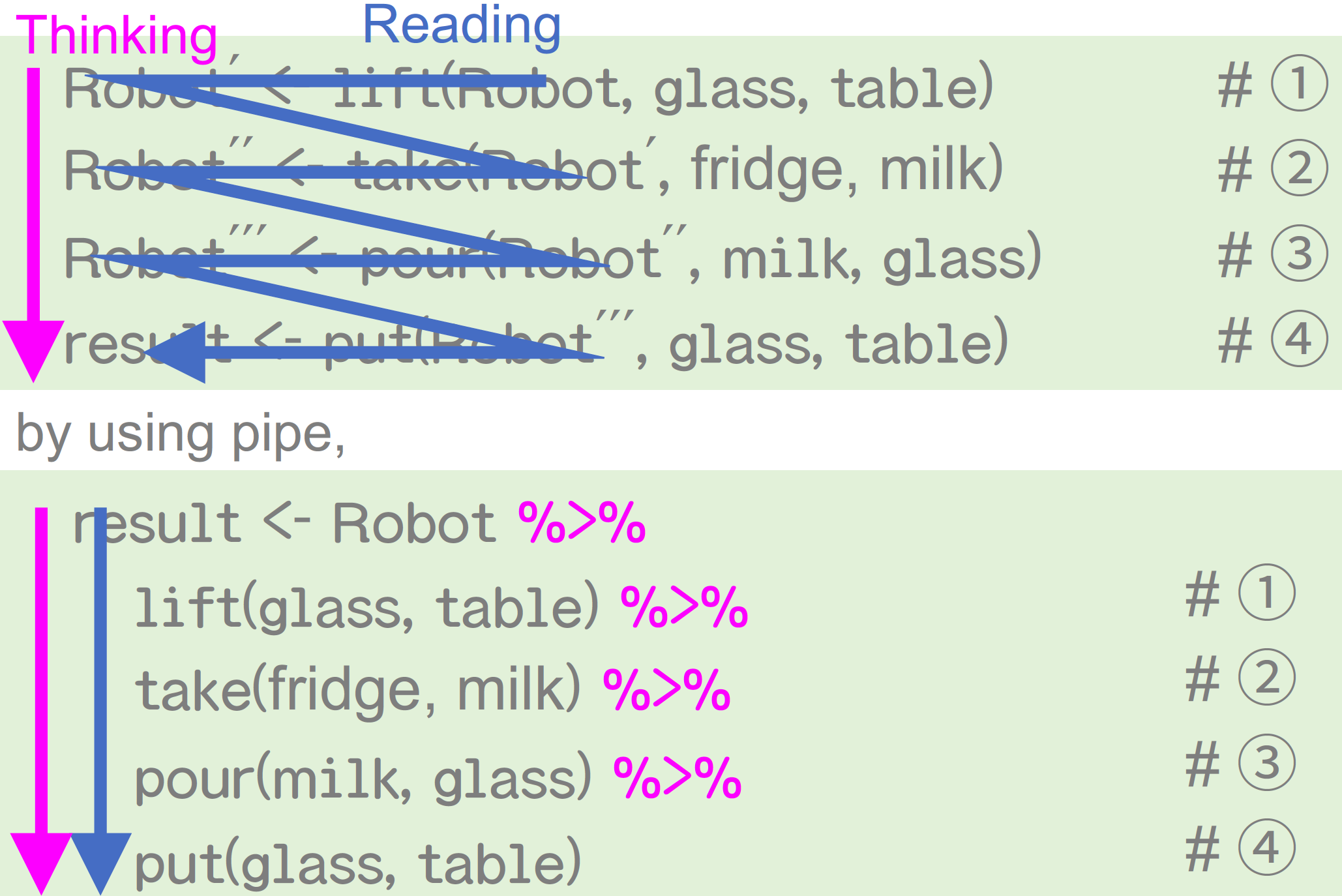
なんでパイプ演算子が必要なのか?
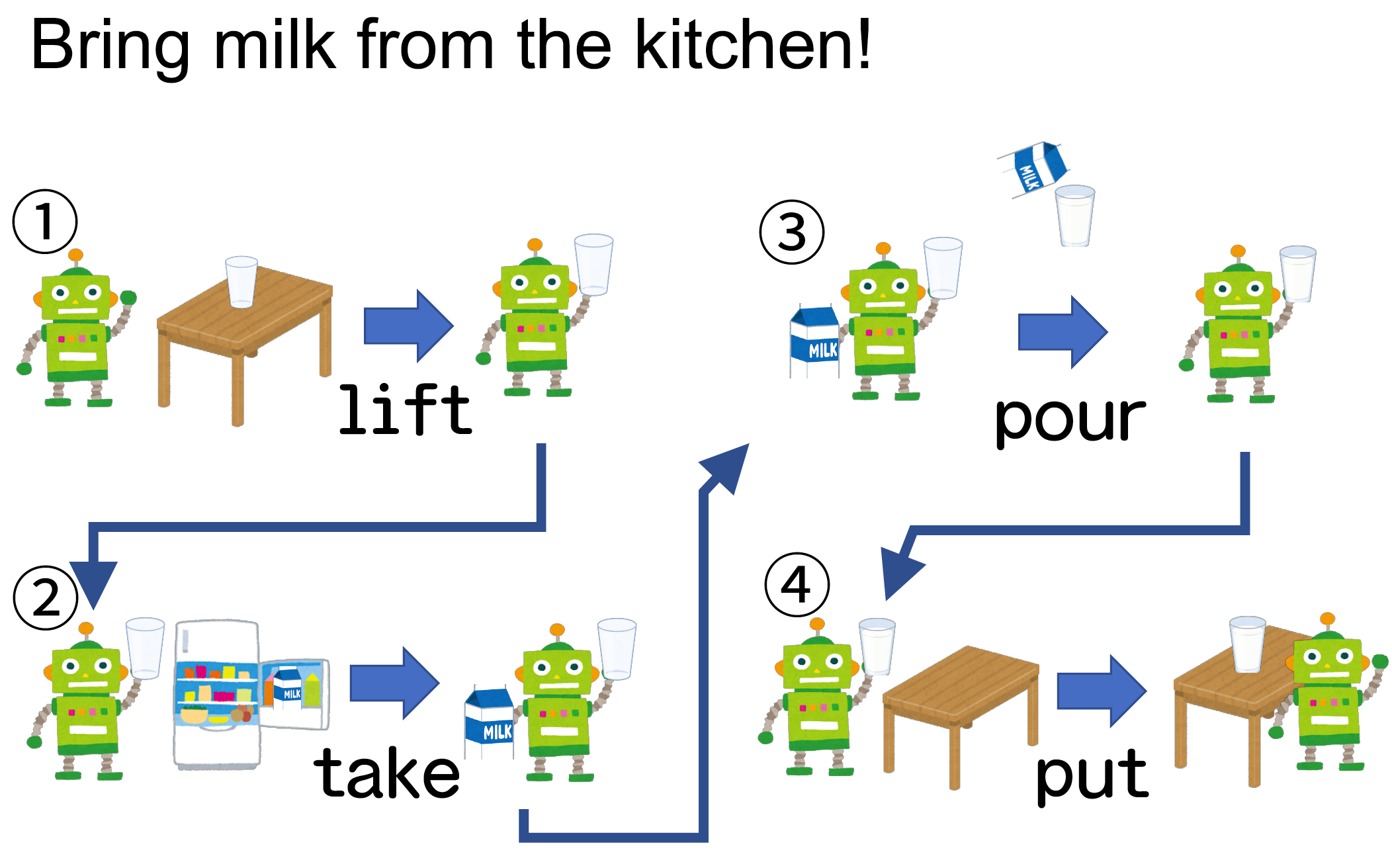
どう書くのか問題

思考の流れと書く流れ
lubridate パッケージ
