初心者セッション
R入門〜データハンドリング
2020/8/1 Tokyo.R #87
はじめに
誰?
- 松村優哉
- Twitter: y__mattu
- 人材・HR Tech系で働くデータ屋さん
- 学生時代: 計量経済学、ベイズ統計、因果推論、マーケティング
- R歴: 6年目
- https://ymattu.github.io/
- http://y-mattu.hatenablog.com/
- Tokyo.R 運営(初心者セッションとか)
![]()
著書(共著)
R ユーザのための RStudio[実践]入門
− tidyverse によるモダンな分析フローの世界−

通称: 「宇宙本」
- RStudio 入門(@y__mattu)
- スクレイピングによるデータ取得(@y__mattu)
- dplyr を中心としたデータハンドリング(@yutannihilation)
- ggplot2 による可視化(@kyn02666)
- R Markdown によるレポーティング(@kazutan)
この資料の目的
- R 初心者(触ったことはあるけど、なんかよくわからない)が、雰囲気を掴む
Contents
- R と RStudio について
- tidyverse について
- テーブルデータの読み込み
- データハンドリング
- 統計学・モデリング・可視化については触れません。
注意
- わりと駆け抜けます
- 参考リンクも多いので資料は後でじっくり御覧ください。
- パッケージ名だけでも覚えてかえっていただけると嬉しいです。
RとRStudioについて
Rとは
- 統計解析およびその周辺環境に強いプログラミング言語
- データの読み込み(ローカル, Webページ, DB)
- データハンドリング
- モデリング
- 可視化
- 最近はWebアプリを作れたり、いろいろできるようになってきた
- プログラミング未経験でも始めやすい(個人的の感想)
R の環境構築
- R のインストールは、CRANから、自分のOSに合ったものを。
- 2020/8/1時点の最新版は、4.0.2
- 3.X.X→4.X.Xの変更点

- おすすめのIDE(統合開発環境)は、RStudio
R のパッケージ
- R のパッケージを使うことで、世界中で開発されている便利な手法を使える
- パッケージに含まれている関数を呼び出すことで、様々な拡張機能を使う
- パッケージは、関数の集まり
- CRANに登録されているものは、
install.packages("パッケージ名")でインストール- 例:
install.packages("ggplot2")
- 例:
パッケージ内の関数の表記
- readr パッケージの read_csv 関数を使いたいとき
tidyverse
tidyverse について
tidyverse(概念)
ざっくり:
- R でやるいろんな操作(データハンドリング、可視化、スクレイピング、分析、etc)を直感的で統一的なインターフェースでできるようになったら嬉しくない?
tidyverse パッケージ
- 上記の概念を実現するためのコアパッケージ群
install.packages("tidyverse")でインストール
tidyverse を読み込み
── Attaching packages ───────────────────────────────────────────────────────────────────────── tidyverse 1.2.1 ──✓ ggplot2 3.3.0 ✓ purrr 0.3.4
✓ tibble 3.0.1 ✓ dplyr 0.8.5
✓ tidyr 1.1.0 ✓ stringr 1.4.0
✓ readr 1.3.1 ✓ forcats 0.4.0── Conflicts ──────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()読み込まれるパッケージ
- ggplot2: 可視化
- dplyr: データの操作
- tidyr: データを tidy に
- readr: データの読み書き
- purrr: 関数型プログラミング
- stringr: 文字列の操作
- forcats: 因子型データの操作
- tibble: tibble というモダンなデータフレーム
データの読み込み
R でのデータ読み込みのベストプラクティス
- RStudio でプロジェクトを作成
- ファイルの位置が分かりやすくなります
- 様々な読み込み関数を使って読み込み
- ローカルにあるファイル(今日の中心)
- データベース(パッケージの紹介のみ)
- Web スクレイピング(またの機会に…)
RStudio でプロジェクトを作成
Project → New Project
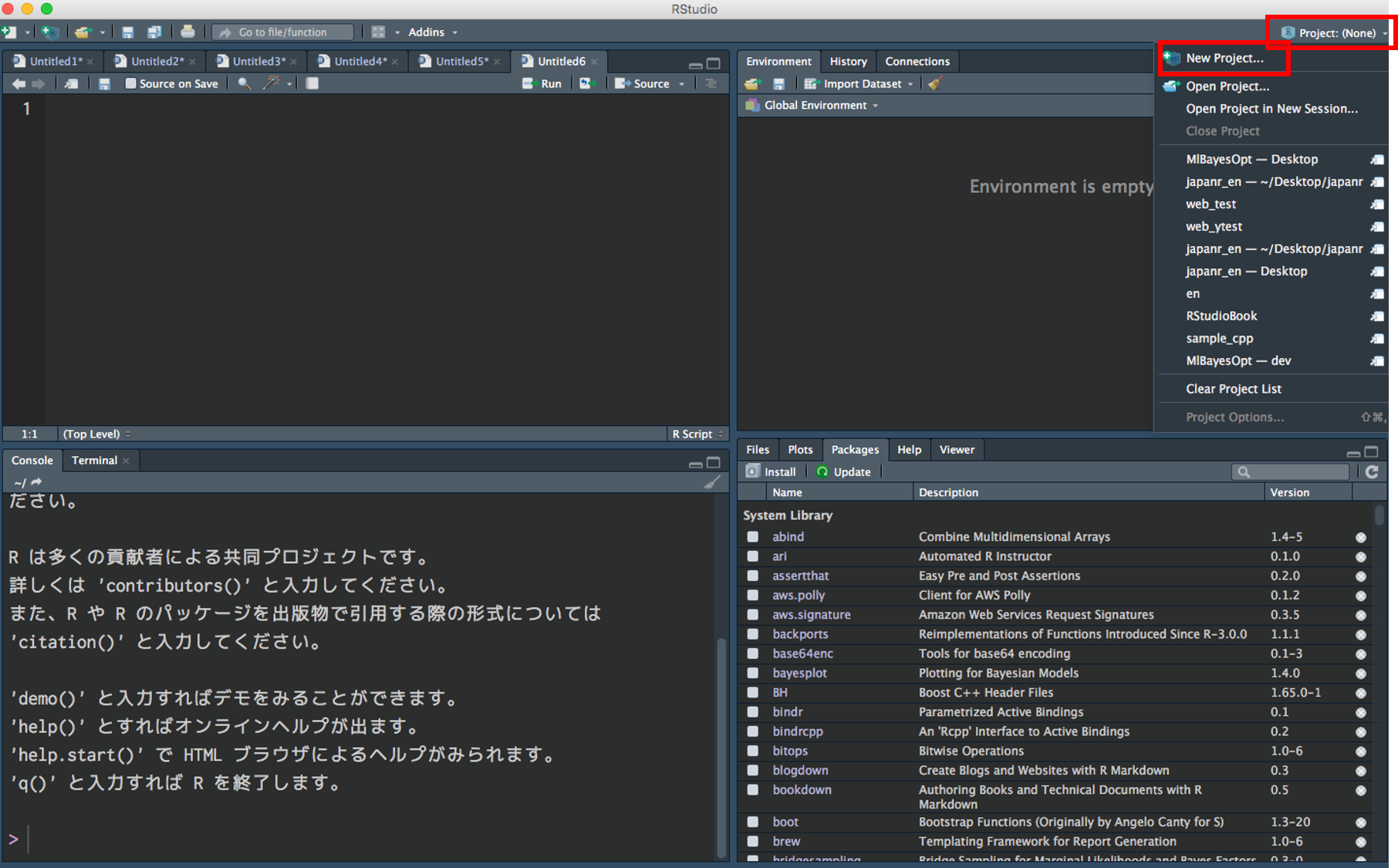
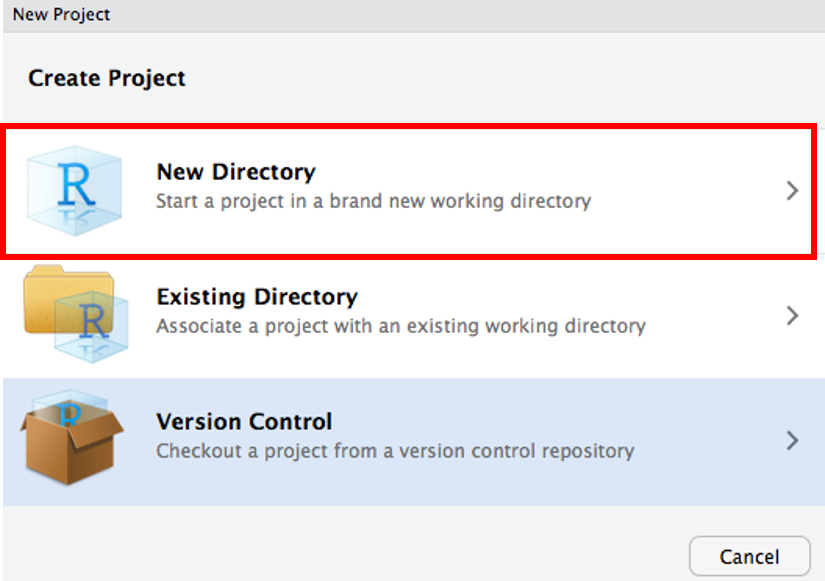
New Directory → New Project
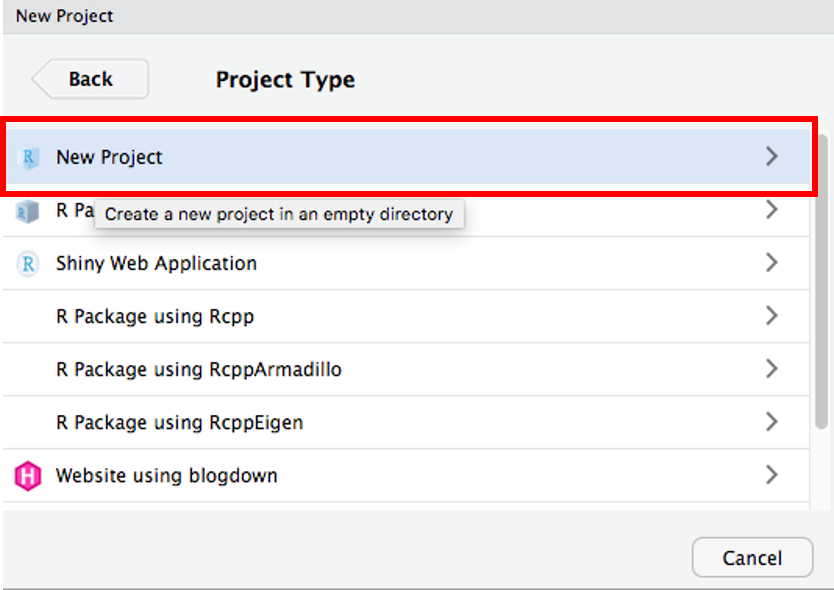
ディレクトリ名を入力
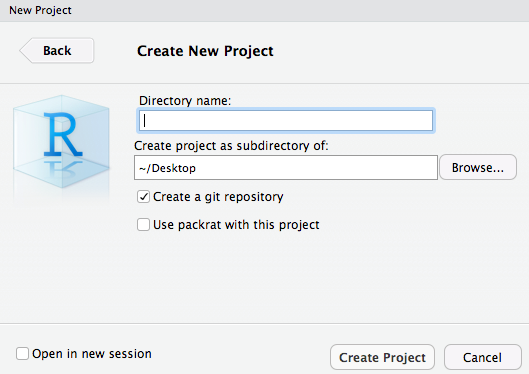
Done!
- 読み込みの関数は、プロジェクトの中のファイルを探しにいきます。
- 書籍によっては
setwd()を書いているものもありますが、RStudioプロジェクトでは必要ありません。
いよいよデータの読み込み
ローカルにあるファイル
csv
read.csv()
- パッケージを使わない方法
- R < 4.0.0 では
stringsAsFactors = TRUEがデフォルトになっているので、stringsAsFactors = FALSEをつけることを推奨します。
readr::read_csv()
- 高速で、列の型をいい感じにやってくれる(オススメ)
data.table::fread()
readr::read_csv()よりも高速- デフォルトでは、data.table というデータフレームとは別の形で読み込まれるのでデータフレームがいいときは
data.table = FALSE
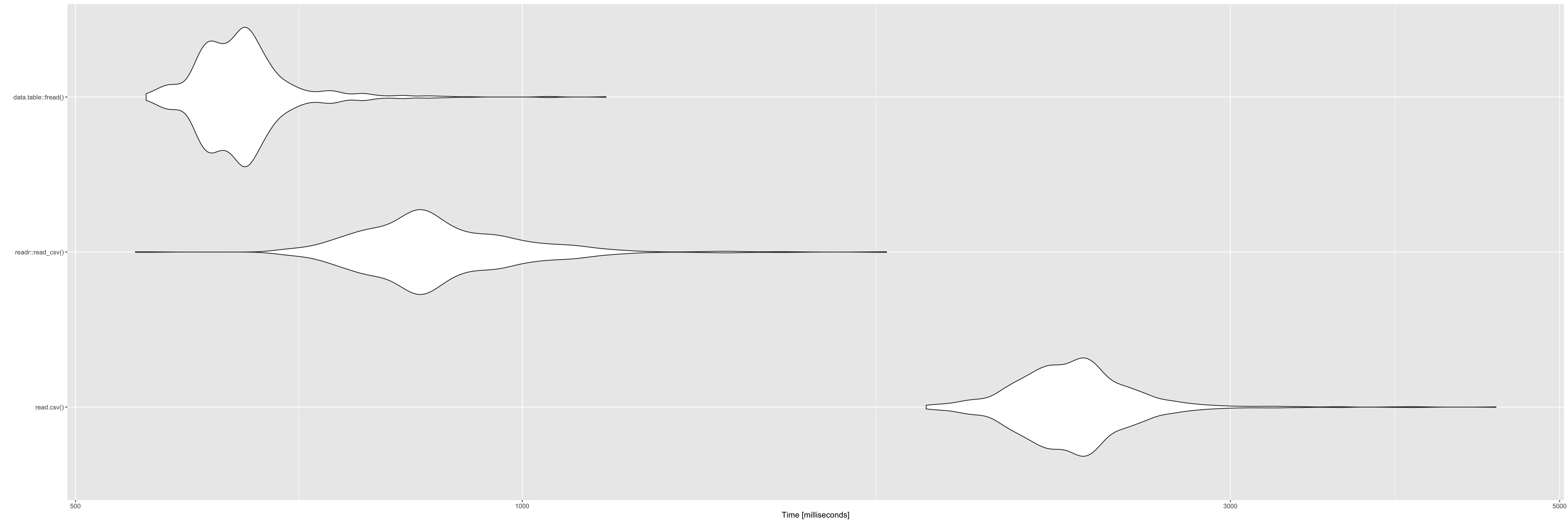
高速ってどのくらい速いの?
速度検証
検証用データ
- ECサイトのログデータ
(を意識して作ったデータ) - csv
- 100 万行× 3 列
- 約 45MB
- https://github.com/ymattu/SampleData
検証環境
- macOS Mojave 10.14.6
- Corei7
- メモリ 16GB
- R 3.6.3
時間を計測
user system elapsed
3.916 0.162 4.294 user system elapsed
0.925 0.051 1.097 user system elapsed
1.349 0.039 0.820 もっとちゃんと時間を知りたい
- microbench パッケージ
- 比較したい関数を1000回ずつとか実行して見やすく表示してくれる
結果1
| expr | min | lq | mean | median | uq | max | neval |
|---|---|---|---|---|---|---|---|
| read.csv() | 1871.3155 | 2222.0066 | 2361.4660 | 2347.1315 | 2452.3060 | 4529.984 | 1000 |
| readr::read_csv() | 548.7358 | 811.9076 | 882.2824 | 860.2287 | 935.6320 | 1759.994 | 1000 |
| data.table::fread() | 557.9172 | 617.1047 | 648.5004 | 643.6659 | 664.1492 | 1138.720 | 1000 |
結果2
tsv
read.delim()
read.delim()は区切り値のファイルを読む標準関数read.csv()はsep = ","をつけたもの
readr::read_tsv()
data.table::fread()
- 区切り値は勝手に判断
その他の区切り値
read.delim()
readr::read_delim()
data.table::fread()
結局?
どれがいいのか
- readrパッケージの
read_***()関数が一番オススメ - 速い、エンコーディングの調整が難しくない(後述)
| read.*** | read_*** | fread | |
|---|---|---|---|
| 速さ(45MB) | 3秒 | 0.8 秒 | 0.6秒 |
| 区切り値の判定ミス | × | × | △ |
| エンコーディング | ○ | ○ | △ |
xlsx, xls
エクセルファイル
エクセルファイルを読み込めるパッケージ
- xlsx
- gdata
- XLConnect
- openxlsx
- readxl → オススメ(速い、列の型をいい感じに読める)
読み込み方
その他の拡張子
SAS(.sas7bdat), STATA(.dta), SPSS(.sav)形式
haven パッケージで読み込み
SAS
STATA
SPSS
文字コードの指定
エンコーディング問題
- Windows の文字コードは Shift-JIS(CP932)
- Mac の文字コードは UTF8
- Windows で作られた(日本語を含む)ファイルを Mac で読むときは
Encoding=cp932 - Mac で作られた(日本語を含む)ファイルを Windows で読むときは
Encoding=UTF8
csv を CP932 で読む
R の標準関数
readr
data.table
関数とかオプションとか
覚えられない
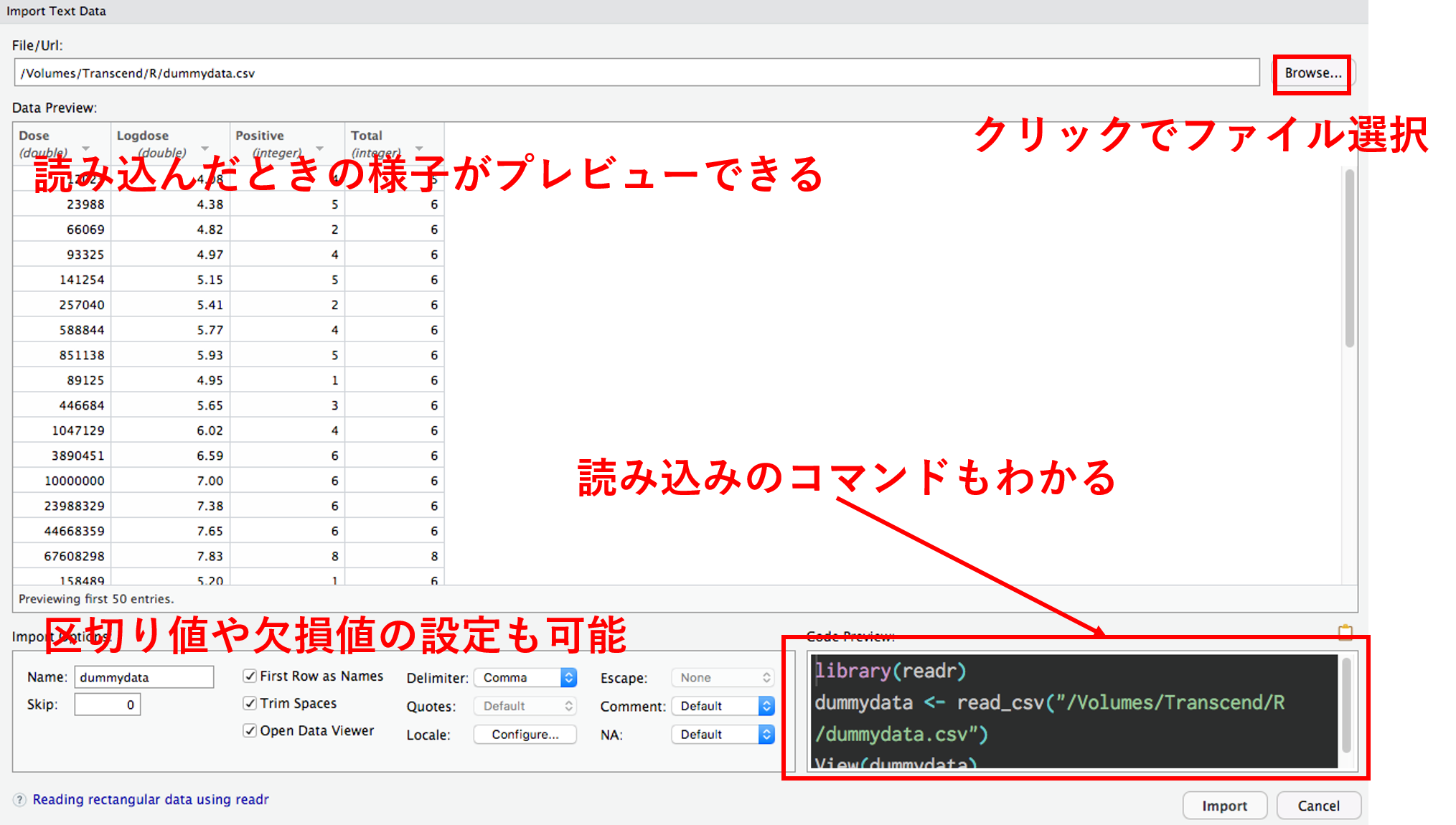
RStudio の GUI 読み込み
RStudio の GUI 読み込み
データベース(クラウド)編
データベースやクラウド上のデータ
- 企業にデータは膨大なのでクラウドにデータを置くことがとても多い
- こういうデータを R から直接触れたら嬉しいですよね!
便利パッケージたち
- DBI(データベースへの接続)
- dplyr(dbplyr)(データベースのテーブル操作)
- sparklyr(Spark, AWS S3)
- bigrquery(Big Query)
- RStudio の Connection タブ
データベース関連の参考資料たち
Web スクレイピング
時間がないので省略

もっといろいろ読み込めないの?
R は他にもいろいろなデータを読み込めます
- 地理情報データ
- 画像
- 音声
- etc…
ググると、意外といろいろ出てきます
データハンドリング
データハンドリングでやること、例えば
- 縦横変換
- 絞り込み(列・行)
- 新しい変数の作成
- 集計
- テーブルのマージ
- etc… →分析できる形に整形
データハンドリング編のコンテンツ
- tidy data
- dplyr
- FAQ
本日の主役は
![]()
![]()
特徴
パッケージを使わないやり方より
- (大きいデータだと特に)
速い - 簡単
≒ わかりやすい - 他の tidyverse のパッケージと相性がいい
データハンドリング編のゴール
- tidy data についてざっくり理解する
- R の dplyr パッケージで簡単な集計ができるようになること
- dplyr や他のパッケージで何ができるのかをなんとなく把握して、「ググり力」を身につける
tidy data
データの形式
2つのデータ形式(例: カテゴリごとの購買金額(千円))
Wide 型
Long 型
tidy data
- 2016 年に Hadley Wickham 氏が提唱
- 定義
- 1つの列が1つの変数を表す
- 1つの行が1つの観測を表す
- 1つのテーブルが1つのデータセットを含む
- Rでのtidy data は、Long 型。
tidyr 1.0.0 (2019/09/11〜)
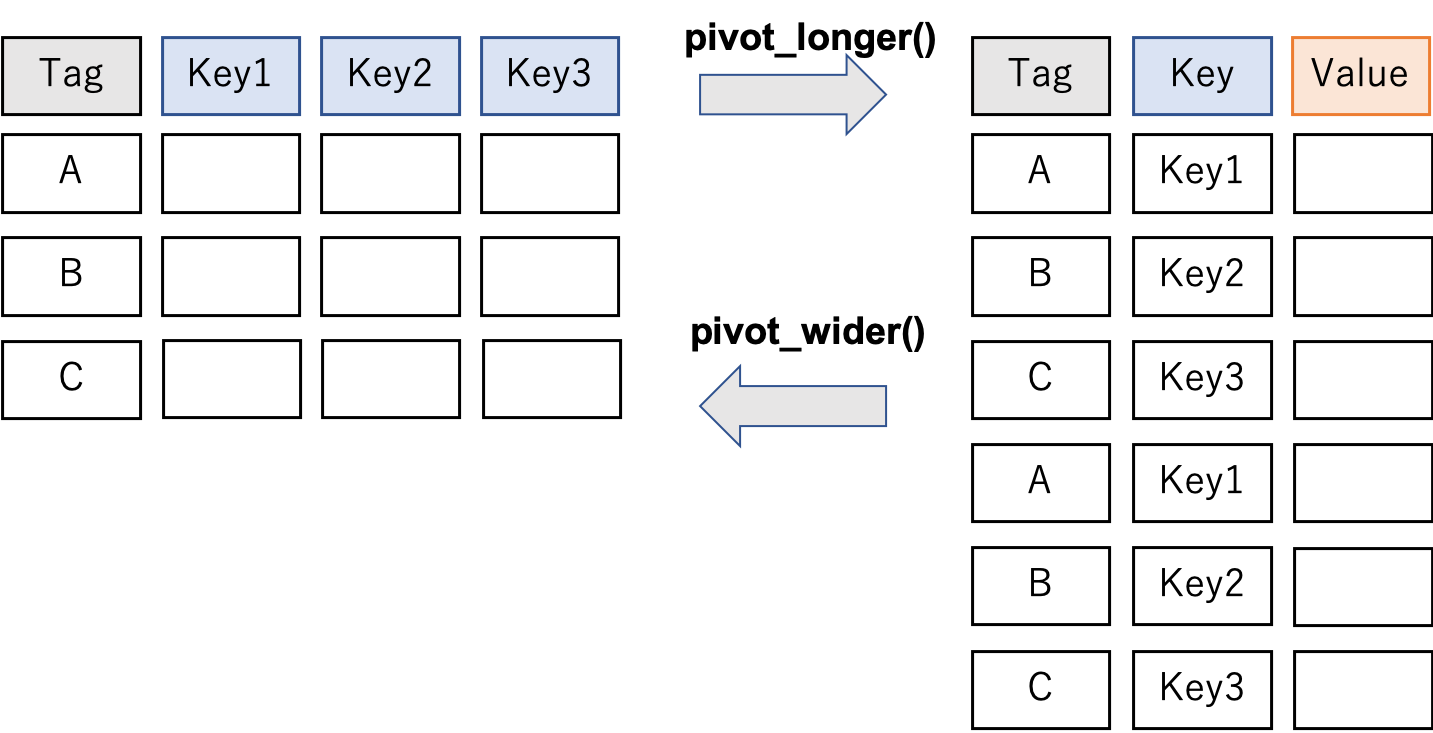
詳しくは
Tokyo.R #79 の応用セッション を参照。
参考: tidyr (〜2019/09/11)
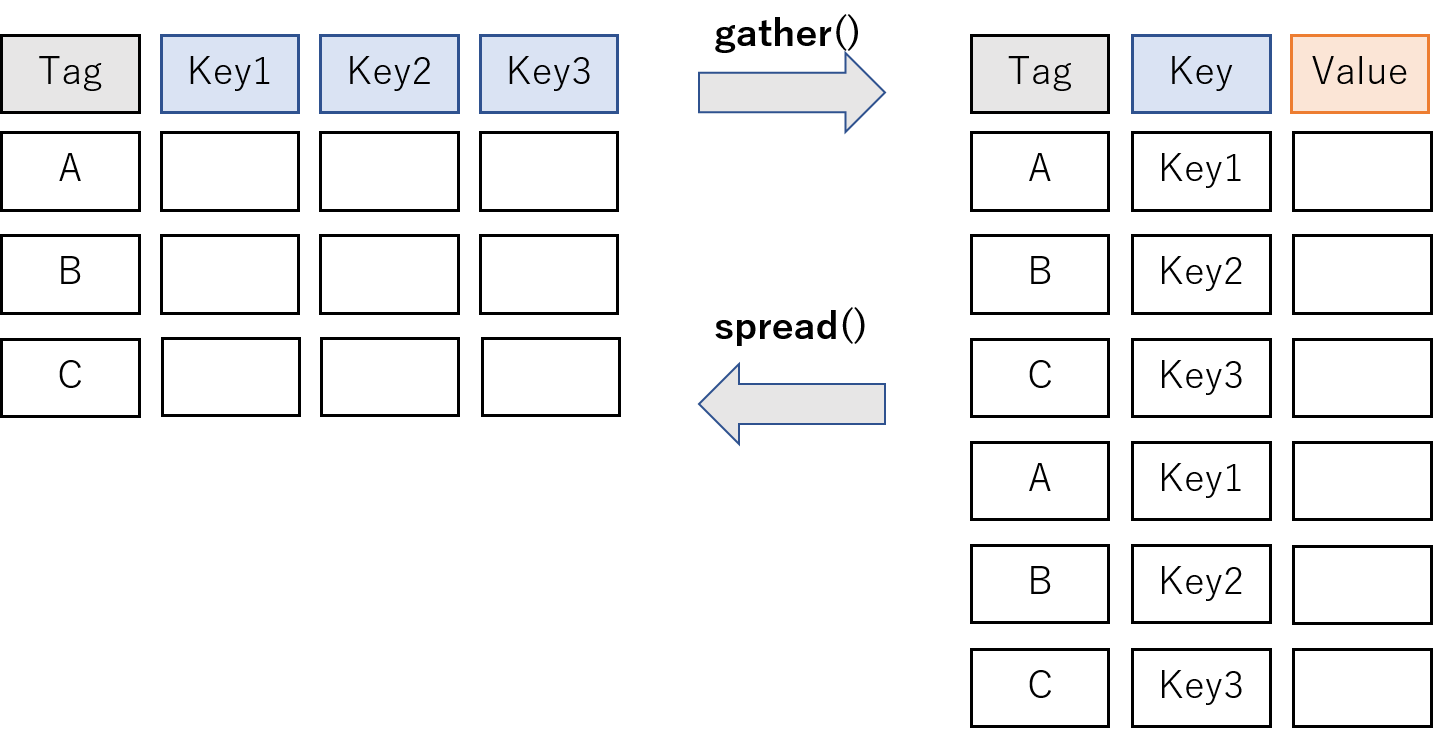
dplyr
本日のデータ
EC サイトのログデータ
- を意識して作ったダミーデータ
- https://github.com/ymattu/sampledata_small
![データの説明]()

データの読み込み方
- RStudio のプロジェクトを作成
- Terminal ペインで以下を実行
git clone https://github.com/ymattu/sampledata_small - readr パッケージの関数で読み込み
dplyr
列選択
%>%
パイプ演算子
- “これまでの処理を次の関数の第 1 引数として渡す」という働き”
[1] 6どう書くのか問題

思考の流れと書く流れ
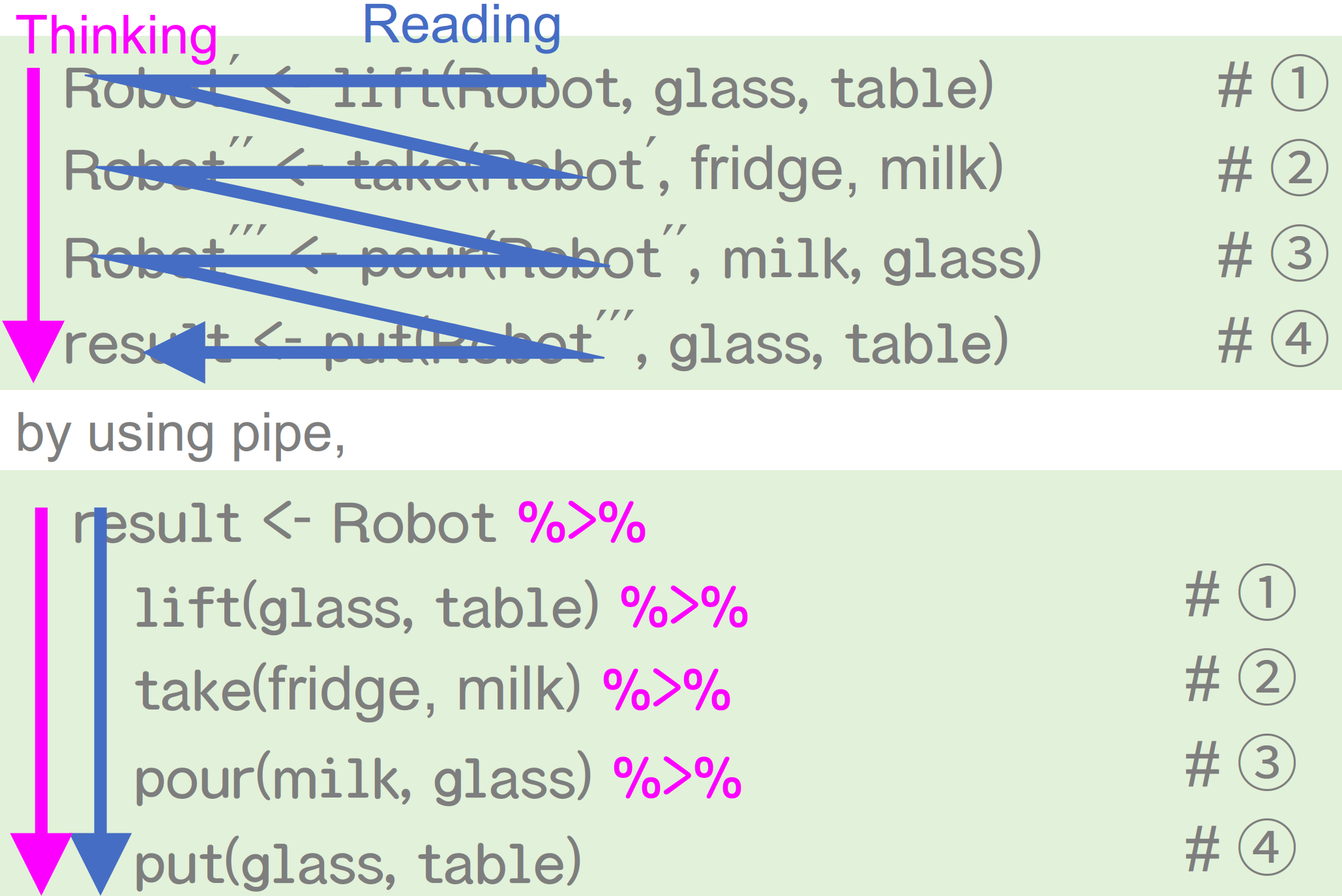
パイプ演算子を使うときのポイント
結果 <- スタート地点 を書いて、やりたい処理をパイプでつないでいく
列選択のやりかたいろいろ 2
例
列追加
- 税込み価格を計算
行の絞り込み
集計
- グルーピング + 集計
ここまでやったところで
パッケージを使わないでできないの?
- できるものもあります。
- select, filter あたりはできます。
- でもめんどくさい
- しかもデータが大きいと遅い
- このあたり、私の過去資料もみてね
- でも
$はお手軽だしよく使います。
$で 1 列だけ取り出す
[1] "雑貨・日用品" "花・グリーン"
[3] "食品" "衣料品"
[5] "ヘルス&ビューティー" "家具・インテリア・家電"日付の操作
lubridate パッケージ

- 日付の操作をよしなにやってくれるパッケージ
[1] "2011-06-04"[1] "2013-01-01"データハンドリングでの使い所
たくさんあるけど例えば
ここから集計につなげる
ユーザー、年ごとに集計
その他、代表的な
(面倒くさい)型たち
文字列型
- stringr パッケージ
- https://kazutan.github.io/kazutanR/stringr-intro.html
因子型(factor 型)
- forcats パッケージ
- https://kazutan.github.io/kazutanR/forcats_test.html
テーブルのマージ
複数のテーブルを考える
a
b
- 基本は SQL と同じ
inner_join()
a
b
left_join()
a
b
full_join()
a
b
anti_join()
a
b
FAQ
dplyr とかだと何で
R の標準関数より速いの?
Answer : C++を使っているから
- dplyrや readrでは、メインの処理を C++でやり、結果を R で受け取る、という構造になっています。
- Rcpp パッケージが活躍!
たくさんのテーブルを join したい!
例えばこんな感じ(a, b, c 3 つのデータ)
x1 x2
1 A 1
2 B 2
3 C 3 x1 x3
1 A TRUE
2 B FALSE
3 D TRUE x1 x4
1 B 10
2 C 11
3 D 12こうする…?
数が増えると大変!たくさんのテーブルを join したい!
Answer : 初心者セッションの範囲をこえますが、
purrrパッケージを使うと簡単です。
purrr パッケージの参考資料→そろそろ手を出す purrr
まとめ
言いたいこと
- (イマドキな)R でのデータ操作では
tidyverseは必須 - 基礎的なことは Tokyo.R 初心者セッションや、宇宙本で!
- 応用は、まずパッケージ名を知ることから(purrr, broom, etc…)
- ぜひ使いこなせるようになりましょう。
本資料について
- revealjs パッケージで作りました。
- 以下の URL で公開しています。
https://ymattu.github.io/TokyoR87/slide.html#/